DATA Camp M1
Mathématiques
Algèbre Linéaire et quelques notions en M1 SEP sur les matrices
Trace d’une matrice
La trace d’une matrice carrée \(A\) est la somme de ses éléments diagonaux : \[\text{Tr}(A) = \sum_{i=1}^{n} a_{ii}\]
Propriétés :
- La trace est linéaire : \[\text{Tr}(A + B) = \text{Tr}(A) + \text{Tr}(B)\]
- Invariance par similitude : \[\text{Tr}(AB) = \text{Tr}(BA)\]
Inverse d’une matrice
Une matrice carré \(A\) d’ordre \(n\) est dite inversible s’il existe \(B\) tel que : \[AB = BA = I_n\]
B est alors noté \(A^{-1}\) l’inverse de A.
Si le déterminant d’une matrice \(A\) est différent de 0 alors la matrice est inversible.
Inverse d’une matrice \((2 \times 2)\)
Inverse d’une matrice \(A\in \mathcal{M}_{2 \times 2}\) de déterminant non nul (\(det(A) = ad -bc \ne 0\)) :
\[A^{-1} = \left(\begin{array}{cc} a & b \\ c & d \end{array} \right)^{-1} = \frac{1}{ad-bc}\left(\begin{array}{cc} d & -b \\ -c & a \end{array} \right)\]
Inverse d’une matrice diagonale
Inverse d’une matrice \(A\in \mathcal{M}_{n \times n}\) de déterminant non nul (\(det(A) = d_1 \times d_2 \times \cdots \times d_n \ne 0\)) : \[D^{-1} = \left(\begin{array}{cccc} d_1 & 0 & \cdots & 0 \\ 0 & d_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & d_n \end{array} \right)^{-1} = \left(\begin{array}{cccc} \frac{1}{d_1} & 0 & \cdots & 0 \\ 0 & \frac{1}{d_2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{1}{d_n} \end{array} \right)\]
Espace vectoriel
Un espace vectoriel est un ensemble de vecteurs qui peuvent être combinés entre eux par des opérations comme l’addition et la multiplication. Ces combinaisons permettent de construire de nouveaux vecteurs dans le même ensemble. Un vecteur \(v = (v_1,...,v_d)\) n’a pas de dimension mais admet une longueur de taille \(d\) ( = d coefficients). Mais, il est d’usage de représenter \(v\) avec sa représentation matricielle notée \(V = \left(\begin{array}{c} v_1 \\ \cdots \\ v_d \end{array} \right)\), matrice de \(d\) lignes et une colonne. On écrit donc \(V = v^t\).
Soient \(v,u\) deux vecteurs d’un espace vectoriel réel de dimension finie muni d’un produit scalaire usuel : \[\langle v, u \rangle_2 = v_1 u_1 + v_2 u_2 + \cdots + v_n u_n\] (le produit scalaire est associée à la norme 2 \(\langle v, v \rangle_2 = \|v\|_2^2\))
Quelques propriétés importantes du produit scalaire :
\(\langle v, v \rangle_2 = \|v\|_2^2 = \sum_{i=1}^{n} v_i^2\) ;
\(\langle v, u \rangle_2 = \langle u, v \rangle_2\) (symétrie) ;
\(\langle v, v \rangle_2 > 0\) si \(v \neq 0\) ;
\(\langle v, w \rangle_2 = v^t w = \text{trace}(vw^t)\) - \(\langle v, w \rangle_2 = \langle w, v \rangle_2\).
Quelques inégalités à connaître :
- Inégalité de Cauchy-Schwarz : \[|\langle x, y \rangle| \leqslant \|x\| \|y\|.\]
- Inégalité triangulaire : \[\|x + y\| \leqslant \|x\| + \|y\|.\]
Orthogonalité
Soient \(v\) et \(w\), deux vecteurs appartenant à un espace vectoriel \(E\) de dimension \(n\), muni du produit scalaire \(\langle \cdot, \cdot \rangle\).
Normalisation d’un vecteur
La normalisation d’un vecteur \(v\) est donnée par : \[x = \frac{v}{\|v\|_2}\] Ainsi, \(\|v\|_2 = 1\).
Deux vecteurs \(v\) et \(u\) sont orthogonaux si leur produit scalaire est nul : \[\langle v, u \rangle = 0\] et on note \(v \perp u\)
Matrice de projection orthogonale
Soit \(E\) un espace vectoriel muni d’un produit scalaire \(\langle \cdot, \cdot \rangle\) et \(W\) un sous-espace vectoriel de \(E\). La projection orthogonale d’un élément \(B\) de \(E\) sur \(W\) est définie par : \[\Pi_W B = \underset{a \in W}{argmin} \|B - a\|_2\] La matrice de projection orthogonale de \(E\) sur \(W\) est notée \(\Pi_W\).
Propriétés
- \(\Pi_W^t = \Pi_W\) ;
- \(\Pi_W^2 = \Pi_W\) ;
- \(\text{trace}(\Pi_W) = \dim(W)\) ;
- \(\Pi_W^\perp = I_E - \Pi_W\).
Construction de matrice de projection orthogonale
Une base \(E\) est un ensemble de vecteurs linéairement indépendants qui permet de décrire tous les vecteurs d’un espace (par combinaison linéaire). On note alors \(E = \text{Vect}(\mathbf{v_1}, \mathbf{v_2}, \dots, \mathbf{v_n})\). Cette notation désigne l’ensemble de tous les vecteurs qui peuvent s’écrire comme une combinaison linéaire de \(\mathbf{v_1}, \mathbf{v_2}, \dots, \mathbf{v_n}\).
Soient \(v_1, \ldots, v_p\), \(p\) vecteurs de \(\mathbb{R}^n\) avec \(p \leqslant n\) formant une base d’un sous-espace \(W\) de \(\mathbb{R}^n\), alors la matrice \(P_W\) de projection sur W est : \[P_W = V (V^t V)^{-1} V^t\] où \(V\) est la matrice dont les colonnes sont les vecteurs \(v_1, \ldots, v_p\).
Si \((v_1, \ldots, v_p)\) est une base orthonormale de W, alors : \[\text{W} = V V^t.\]
Procédé d’orthogonalisation de Gram-Schmidt
Le but du procédé de Gram-Schmidt est de prendre un ensemble de vecteurs linéairement indépendants \(( {v_1, v_2, \ldots, v_n})\) et de produire un ensemble de vecteurs orthogonaux \(( {u_1, u_2, \ldots, u_n} )\) qui engendrent le même sous-espace.
Étapes du Procédé
Le premier vecteur orthogonal ( \(u_1\) ) est le premier vecteur de l’ensemble original : \[u_1 = v_1\]
Pour chaque vecteur \(( v_k )\) (où $ k $), on soustrait les projections orthogonales de \(( v_k )\) sur les vecteurs orthogonaux précédemment calculés \(( u_1, u_2, \ldots, u_{k-1})\) : \[ u_k = v_k - \sum_{j=1}^{k-1} \frac{\langle v_k, u_j \rangle}{\langle u_j, u_j \rangle} u_j \]
Si l’on souhaite obtenir une base orthonormale, chaque vecteur \(( u_k )\) est normalisé pour obtenir \(( e_k )\) : \[ e_k = \frac{u_k}{||u_k||} \]
Base duale
Pour une base \(\{e_1, e_2, \ldots, e_n\}\) d’un espace vectoriel \(E\), la base duale \((e^1, e^2, \ldots, e^n)\) est définie par : \[e^i(e_j) = \delta_{ij}\] où \(\delta_{ij}\) est le symbole de Kronecker.
La base duale permet de définir des formes linéaires et de travailler avec des espaces vectoriels de manière plus abstraite.
Pour plus d’informations sur la base duale cliquez ici
Diagonalisation d’une matrice
Une matrice carrée \(A\) est dite diagonalisable s’il existe une matrice diagonale \(D\) et une matrice inversible \(P\) telles que : \[A = PDP^{-1}\] \(D\) est une matrice diagonale contenant les valeurs propres de \(A\) et \(P\) est formé de vecteurs propres dans l’ordre des valeurs propres mis dans \(D\).
Si les vecteurs propres sont normalisés alors \(P^{-1} = P^t\) et \(A = PDP^t\).
Diagonalisation d’une matrice symétrique réelle
Pour les matrices symétriques réelles, on peut toujours trouver une base orthonormale de vecteurs propres, ce qui permet de les diagonaliser par une matrice orthogonale \(Q\) : \[A = QDQ^T\]
Probabilités
Qu’est-ce qui caractérise une variable aléatoire ?
En théorie, on représente la moyenne comme l’espérance : Dans le cas discret : \[E(X) = \sum k \cdot P(X = k)\] \[k \in X(\Omega)\] Alors que dans le cas continu : \[E(X) = \int x \cdot f_X(x) \, dx\] \[x \in X(\Omega)\]
Fonction de répartition
La fonction de répartition est définie par : \[F_X(x) = P(X \leqslant x)\]
Pour tout \(x\), \(0 \leqslant F_X(x) \leqslant 1\), \(F_X\) est une fonction croissante. De plus, \(\lim_{x \to -\infty} F_X(x) = 0\) et \(\lim_{x \to \infty} F_X(x) = 1\)
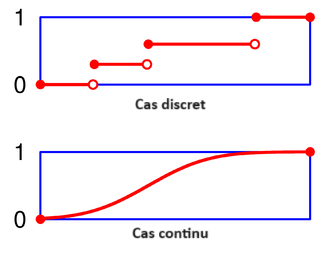
Loi marginale
La loi marginale de X est définie comme suit : \[f_X(x) = \int f_{X, Y}(x, y) \, dy, \text{ où } -\infty < x < \infty,\] dans le cas continu, ou encore : \[f_X(x_i) = \sum p_{ij}, \text{ où } j \text{ tel que } y_j \leqslant y\]
Si X et Y sont indépendants, alors : \[f_{X, Y}(x, y) = f_X(x) \cdot f_Y(y)\]
Savoir-faire de probabilités
Centrage et réduction
Le centrage consiste à localiser la distribution autour de l’origine et la réduction consiste à normaliser la dispersion. On crée une nouvelle variable aléatoire \(Y\) issu de \(X\) dont l’espérance est null et la variable est égale à 1. \[Y = \frac{X - E(X)}{\sqrt{\sigma(X)^2}}\] où \(E(X)\) représente l’espérance de X et \(\sigma^2\) est la variance de \(X\).
Moments d’ordre r
Le moment d’ordre r est défini par : \[\mu_r = E(X^r)\] Le moment centré d’ordre r est défini par : \[\mũ_r = E((X - E(X))^r)\]
Couples aléatoires
Fonction de répartition et densité
La fonction conjointe est appelée la distribution conjointe de X et Y. \[F_{X, Y}(x, y) = P(X \leqslant x \cap Y \leqslant y)\]
Dans le cas continu, la fonction définie par : \[f_{X, Y}(x, y) = \frac{\partial^2 F_{X, Y}(x, y)}{\partial x \partial y}\] est la densité conjointe du couple (X, Y). On a donc : \[F_{X, Y}(x, y) = \int \int f_{X, Y}(t, u) \, dt \, du, \text{ où } -\infty < x, y < +\infty,\]
Dans le cas discret, on définit la fonction de probabilité conjointe : \[P(X = x_i, Y = y_j) = p_{ij}\] On a donc : \[F_{X, Y}(x, y) = \sum \sum p_{ij}, \text{ où } x_i \leqslant x \text{ et } y_j \leqslant y\]
Covariance
La covariance mesure l’intensité de la relation linéaire entre deux variables aléatoires X et Y. Elle est définie comme suit : \[Cov(X, Y) = E(XY) - E(X) \cdot E(Y)\]
Si X et Y sont indépendants, alors : \[Cov(X, Y) = 0\]
Il est important de noter que la réciproque n’est pas vraie : la covariance n’implique pas nécessairement l’indépendance entre X et Y.
Propriétés à connaître de l’espérance, variance et covariance
Espérance \[\mathbb{E}(aX + bY) = a\mathbb{E}(X) + b\mathbb{E}(Y)\]
\[\mathbb{E}(a) = a\] Variance
\[\text{Var}(aX) = a^2\text{Var}(X)\]
\[\text{Var}(a) = 0\]
\[\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) + 2\text{Cov}(X,Y)\]
\[ \text{Si } X \coprod Y \text{ alors } \text{Var}(X+Y) = \text{Var}(X) + \text{Var}(Y)\]
Covariance \[\text{Cov}(X, Y) = \text{Cov}(Y, X)\]
\[\text{Cov}(aX + bY, cU + dV) = ac\text{Cov}(X, U) + ad\text{Cov}(X, V) + bc\text{Cov}(Y, U) + bd\text{Cov}(Y, V)\]
Vecteurs aléatoires
L’espérance d’un vecteur aléatoire \(X = (X_1, X_2, \vdots, X_n)^t\) de X est le vecteur des espérances de \(X_i\) c’est-à-dire \(\mathbb{E}(X) = \left(\begin{array}{c} E(X_1) \\ \ldots \\ \mathbb{E}(X_n) \end{array} \right)\).
L’espérance reste linéaire, en particulier pour \(X\) et \(Y\) appartenant à \(R^n\) on a :
\[\mathbb{E}(aX + bY) = a\mathbb{E}(X) + b\mathbb{E}(Y) \text{ où } a,b \in \mathbb{R}\] \[\mathbb{E}(AX + B) = A\mathbb{E}(X)+B\]
La variance-covariance de X notée \(\Sigma\) une matrice \(n \times n\) où chaque élément \(\Sigma_{ij}\) représente la covariance entre les variables aléatoires \(X_i\) et \(X_j\). Les éléments diagonaux de \(\Sigma\) correspondent aux variances des composantes \(X_i\), tandis que les éléments hors-diagonaux représentent les covariances entre les différentes composantes de \(X\). La matrice \(\Sigma\) est donc définie comme suit :
\[\Sigma = \begin{pmatrix} \text{Var}(X_1) & \text{Cov}(X_1, X_2) & \dots & \text{Cov}(X_1, X_n) \\ \text{Cov}(X_2, X_1) & \text{Var}(X_2) & \dots & \text{Cov}(X_2, X_n) \\ \vdots & \vdots & \ddots & \vdots \\ \text{Cov}(X_n, X_1) & \text{Cov}(X_n, X_2) & \dots & \text{Var}(X_n) \end{pmatrix}\] \[ \Sigma_{AX + B} = A\Sigma_X(X)A^t\] où \(\Sigma\) est la variance de X et A,B sont des matrices (deterministe)
Notions de convergence
Si l’on pense à des données, vues comme réalisation de variables aléatoires \(X_1, \ldots, X_n\), il serait intéressant de se poser la question de savoir comment évolue cette suite lorsque \(n\) tend vers l’infini.
On dit que \((X_n)\) converge presque sûrement vers \(X\) et on note \(X_n \underset{n \rightarrow \infty}{\xrightarrow{\text{p.s.}}}{} X\) si et seulement si : \(P\left(\underset{n\to+\infty}{\lim} X_n = X\right) = 1\)
On dit que \((X_n)\) converge en probabilité vers \(X\) et on note \(X_n \underset{n \rightarrow \infty}{\xrightarrow{\text{p}}} X\) si et seulement si : \(\forall \varepsilon > 0, \quad P(|X_n - X| > \varepsilon) \rightarrow 0\)
On dit que \((X_n)\) converge en loi vers \(X\) et on note \(X_n \xrightarrow{\mathcal{L}} X\) si et seulement si : \(F_{X_n} \underset{n \to +\infty}{\rightarrow} F_X\) Où \(F_X\) dénote la fonction de répartition de \(X\).
On dit que \((X_n)\) converge en moyenne quadratique vers \(X\) et on note \(X_n \underset{n \rightarrow \infty}{\xrightarrow{m.q.}}X\) si et seulement si : \(\mathbb{E}((X_n - X)^2) \rightarrow 0\)
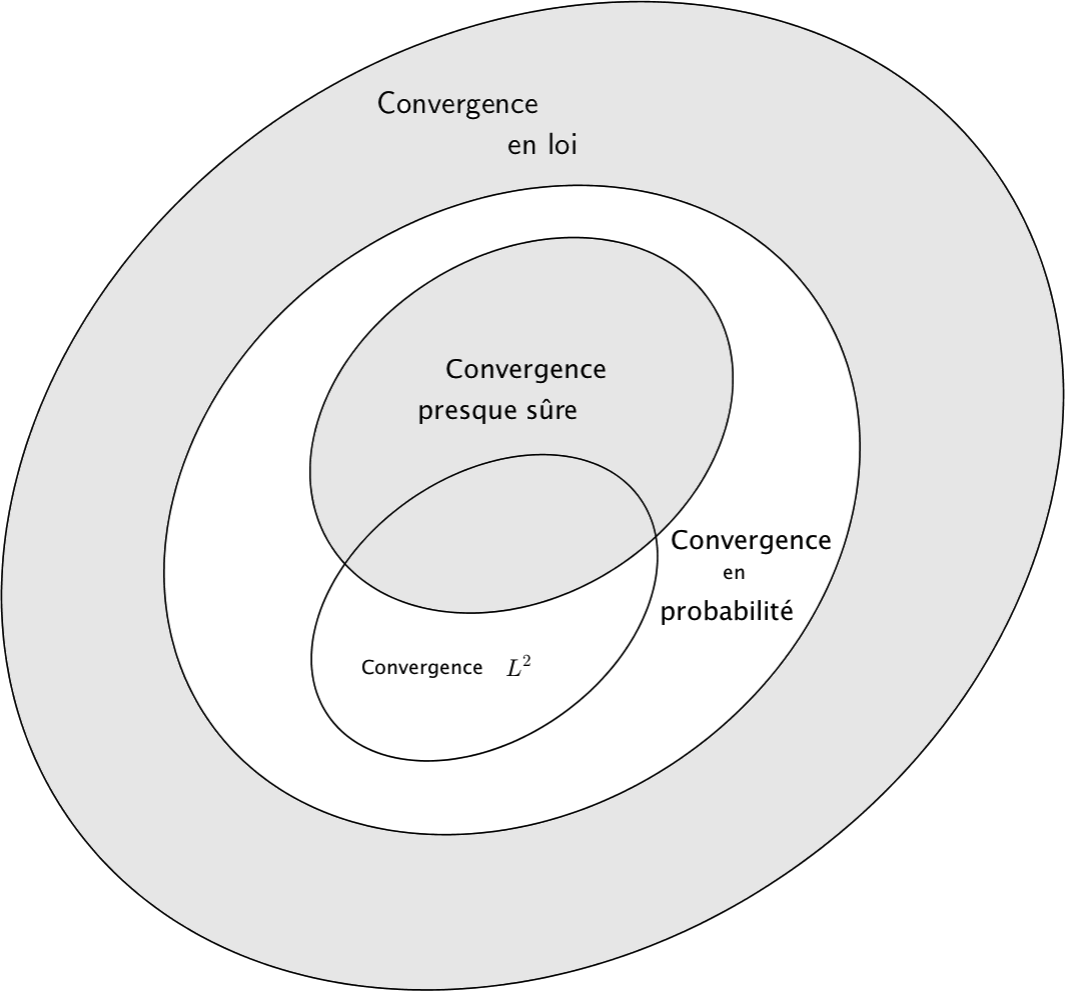
Loi faible des grands nombres
Soit \(X_1, \ldots, X_n\) une suite de variables aléatoires indépendantes et de même loi telles que : \(\mathbb{E}(X_i) = \mu\) et \(\text{Var}(X_i) = \sigma^2\) alors :
\[\frac{1}{n} \sum_{i=1}^{n} X_i \xrightarrow{P} \mu \]
Soit \(Z_1,\ldots, Z_n\) une suite de vecteurs aléatoires où \(Z_i\) est un vecteur aléatoire à p dimensions : \[Z_i = \begin{pmatrix} Z_{i1} \\ Z_{i2} \\ \vdots \\ Z_{ip} \end{pmatrix}\]
On suppose que les vecteurs \(Z_1, Z_2, \dots, Z_n\) sont i.i.d. , avec une espérance \(\mathbb{E}[Z_i] = \mu\), où \(\mu\) est un vecteur constant de dimension \(p\) et chaque composante \(Z_{ij}\) a une variance finie. \[\mu = \begin{pmatrix} \mu_1 \\ \mu_2 \\ \vdots \\ \mu_p \end{pmatrix}\]
Alors, la moyenne empirique \(\bar{Z}_n\) converge en probabilité vers l’espérance \(\mu\) lorsque \(n \to \infty\) :
\[\bar{Z}_n = \frac{1}{n} \sum_{i=1}^{n} Z_i = \begin{pmatrix} \frac{1}{n} \sum_{i=1}^{n} Z_{i1} \\ \frac{1}{n} \sum_{i=1}^{n} Z_{i2} \\ \vdots \\ \frac{1}{n} \sum_{i=1}^{n} Z_{ip} \end{pmatrix} \xrightarrow{P} \mu \quad \text{lorsque} \quad n \to \infty\]
Théorème central limite
Soit \(X_1, \ldots, X_n\) une suite de variables aléatoires indépendantes et de même loi telles que : \(\mathbb{E}(X_i) = \mu\) et \(\text{Var}(X_i) = \sigma^2\), alors : \[\sqrt{n}\frac{\overline{X}_n - \mu}{\sigma} \xrightarrow{\mathcal{Loi}} \mathcal{N}(0, 1)\]
Soit \((Z_n)_{n \in \mathbb{N}^*}\) une suite de vecteurs aléatoires de dimension \(p\), indépendants et de même loi, admettant une matrice de variance-covariance \(\Sigma_Z\). La suite des vecteurs \(\overline{Z}_n = \frac{1}{n} \sum_{k=1}^n Z_k\), \(n \in \mathbb{N}^*\) vérifie \[\sqrt{n}\Sigma_Z^{-\frac{1}{2}}\left(\overline{Z}_n-\mathbb{E}(Z) \right)\xrightarrow{\mathcal{Loi}} \mathcal{N}_p(0, 1),\] où \(\Sigma_{Z}^{-1/2}\) désigne la “racine carrée” de l’inverse de \(\Sigma_Z\).
Tableau des lois usuelles
Les variables \(X_1, \ldots, X_n\) sont indépendantes et identiquement distribuées (i.i.d.) si et seulement si :
Dans le cas discret : \[P(X_1 = x_1, \ldots, X_n = x_n) = P(X_1 = x_1) \times \ldots \times P(X_n = x_n)\]
Dans le cas continu :
\[P(X_1 \leq x_1, X_2 \leq x_2, \ldots, X_n \leq x_n) = P(X_1 \leq x_1) \cdot P(X_2 \leq x_2) \cdots P(X_n \leq x_n)\]
Ces tableaux récapitulent les lois usuelles que vous pourrez rencontrer dans différents cours du master.
| Nom | Notation | \(X(\Omega)\) | \(P(X = k)\) | \(E[X]\) | \(Var(X)\) |
|---|---|---|---|---|---|
| Uniforme | \(X \sim U(\{1, 2, \ldots, n\})\) | \(\{1, 2, \ldots, n\}\) | \(\frac{1}{n}\) | \(\frac{n+1}{2}\) | \(\frac{n^2-1}{12}\) |
| Bernouilli | \(X \sim B(p), 0 < p < 1\) | \(\{0, 1\}\) | \(P(X = 1) = p\) | \(p\) | \(p(1-p)\) |
| \(P(X = 0) = 1 - p\) | |||||
| Binomiale | \(X \sim B(n, p), 0 < p < 1\) | \(\{1, 2, \ldots, n\}\) | \(C_k^n p^k (1 - p)^{n-k}\) | \(np\) | \(np(1-p)\) |
| Géométrique | \(X \sim G(p), 0 < p < 1\) | \(\mathbb{N}^{*}\) | \(p(1-p)^{k}\) | \(\frac{1-p}{p}\) | \(\frac{1-p}{p^2}\) |
| Poisson | \(X \sim P(\lambda), \lambda > 0\) | \(\mathbb{N}\) | \(\frac{\lambda^k}{k!}e^{-\lambda}\) | \(\lambda\) | \(\lambda\) |
| Nom | Notation | \(X(\Omega)\) | \(f_X(x)\) | \(E[X]\) | \(V(X)\) |
|---|---|---|---|---|---|
| Uniforme | \(X \sim U([a, b]), a < b\) | \([a, b]\) | \(\frac{1}{b - a}1_{[a, b]}(x)\) | \(\frac{a + b}{2}\) | \(\frac{(a - b)^2}{12}\) |
| Exponentielle | \(X \sim \mathcal{E}(\lambda), \lambda > 0\) | \(\mathbb{R}^+\) | \(\lambda e^{-\lambda x}1_{\mathbb{R}^+}(x)\) | \(\frac{1}{\lambda}\) | \(\frac{1}{\lambda^2}\) |
| \(\mathcal{E}(\lambda) = \gamma(1, \lambda)\) | |||||
| Normale ou Gaussienne | \(X \sim N(m, \sigma^2), \sigma > 0\) | \(\mathbb{R}\) | \(\frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{(x - m)^2}{2\sigma^2}\right)\) | \(m\) | \(\sigma^2\) |
| Gamma | \(X \sim \gamma(\alpha, \theta), \alpha > 0, \theta > 0\) | \(\mathbb{R}^+\) | \(\frac{\theta^\alpha}{\Gamma(\alpha)}x^{\alpha - 1}e^{-\theta x}1_{\mathbb{R}^+}(x)\) | \(\frac{\alpha}{\theta}\) | \(\frac{\alpha}{\theta^2}\) |
| \(\Gamma(\alpha) = \int_0^\infty e^{-x}x^{\alpha-1} \, dx\) | |||||
| Khi-2 | \(X \sim \chi^2(n), n \in \mathbb{N}^+\) | \(\mathbb{R}^+\) | \(\gamma\left(\frac{n}{2}, \frac{1}{2}\right)\) | \(n\) | \(2n\) |
| \(Y_1, Y_2, \ldots, Y_n \text{ i.i.d},\) | |||||
| \(Y_i \sim \mathcal{N}(0, 1), \quad X = \sum_{i=1}^{n} Y_i^2\) | |||||
| Bêta | \(X \sim B(\alpha, \theta), \alpha > 0, \theta > 0\) | \([0, 1]\) | \(\frac{x^{\alpha-1}(1-x)^{\theta-1}}{B(\alpha, \theta)}1_{[0, 1]}(x)\) | \(\frac{\alpha}{\alpha+\theta}\) | \(\frac{\alpha\theta}{(\alpha+\theta)^2(\alpha+\theta+1)}\) |
| \(B(\alpha, \theta) = \int_0^1 x^{\alpha-1}(1-x)^{\theta-1} \, dx\) | |||||
| \(X = \frac{Z}{1 + Z}, \quad Z \sim B'(\alpha, \theta)\) | |||||
| Bêta (prime) | \(Z ∼ B'(\alpha, \theta), \alpha > 0, \theta > 0\) | \(\mathbb{R}^+\) | \(\frac{z^{\alpha-1}}{B(\alpha,\theta) \cdot (1+z)^{\alpha+\theta}} \cdot 1_{\mathbb{R}^+}(z)\) | \(\frac{\alpha}{\theta - 1}\) | \(\frac{\alpha(\alpha+\theta-1)}{(\theta-1)^2(\theta-2)}\) |
| \(X \sim \gamma(\alpha, 1), Y \sim \gamma(\theta, 1), X \perp\!\!\!\perp Y\) | \(\theta > 1\) | \(\theta > 2\) | |||
| Student T | \(T \sim T(n), n \in \mathbb{N}^*\) | \(\mathbb{R}\) | \(\frac{\left(1 + \frac{t^2}{n}\right)^{-(n+\frac{1}{2})}}{\sqrt{n}\cdot B(\frac{1}{2},\frac{n}{2})}\) | \(0\) | \(\frac{n}{n - 2}\) |
| \(T = \frac{X}{\sqrt{Y/n}}, \quad T^2/n \sim B'(1/2, n/2)\) | \(n > 2\) | ||||
| Fisher | \(X \sim F(n, m)\) | \(\mathbb{R}^+\) | \(\frac{Kx^{n/2-1}}{(m+nx)^{(n+m)/2}}1_{\mathbb{R}^+}(x)\) | \(\frac{m}{m-2}\) | \(\frac{2m^2(n+m-2)}{n(m-2)^2(m-4)}\) |
| \(N \sim \chi^2(n), M \sim \chi^2(m), N \perp\!\!\!\perp M\) | \(m > 2\) | \(m > 4\) |
Connaître les densités ne servirait pas à grand chose, mais ceci nous évitera de parler de lois dont nous ne connaissons pas leur construction.
Statistique inférentielle
Echantillon / Estimateur
Le point de départ est un vecteur (ou un tableau dans le cas multidimensionnel) de données. Ces données peuvent être vues comme les réalisations \((x_1, x_2, \ldots, x_n)\) d’une variable aléatoire \(X\) qui dépend d’un certain paramètre \(\theta\) que nous allons chercher à estimer. Pour ce faire, nous allons construire un échantillon de cette variable. Un échantillon \((X_1, X_2, \ldots, X_n)\) est un n-uplet de variables aléatoires indépendantes qui suivent toutes la même loi (celle de \(X\)). Un estimateur de \(\theta\) est une fonction \(\hat{\theta} = f(X_1, X_2, \ldots, X_n)\) de notre échantillon, qui possède une loi de probabilité. Lorsque l’aléa est réalisé, \(\hat{\theta}(\omega) = f(x_1, x_2, \ldots, x_n)\) est une estimation de \(\theta\). Le but de ce cours est de construire le meilleur estimateur possible de \(\theta\).
Estimateur sans biais
Pour que l’estimation soit bonne, il faut que \(\hat{\theta}\) soit proche de \(\theta\). Comme \(\hat{\theta} = f(X_1, X_2, \ldots, X_n)\) est une variable aléatoire, on ne peut imposer de condition qu’à sa valeur moyenne.
On définit ainsi le biais : \[b_n(\hat{\theta}, \theta) = \mathbb{E}(\hat{\theta}_n) - \theta\]
Un estimateur est dit sans biais si \(b_n(\hat{\theta}, \theta) = 0\), c’est-à-dire : \[\mathbb{E}(\hat{\theta}_n) = \theta\]
Le plus souvent, on veut estimer la moyenne et la variance.
Estimations de la moyenne
Soit un échantillon de variables aléatoires \(X_1, X_2, \dots, X_n\) tirées d’une population avec une moyenne \(\mu = \mathbb{E}[X_i]\).
La moyenne empirique (ou moyenne d’échantillon) est définie par :
\[\hat{\mu} = \frac{1}{n} \sum_{i=1}^{n} X_i\]
L’espérance de cet estimateur est :
\[\mathbb{E}[\hat{\mu}] = \mathbb{E}\left[\frac{1}{n} \sum_{i=1}^{n} X_i\right] = \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}[X_i] = \mu\]
La moyenne empirique est donc non biaisée. Son espérance est égale à la vraie moyenne de la population.
Estimation de la variance
Soit \(X_1, X_2, \dots, X_n\) un échantillon de variables aléatoires \(X_i\) avec une variance \(\sigma^2 = \mathbb{V}[X_i]\).
L’estimateur classique de la variance basé sur l’échantillon est :
\[\hat{\sigma}^2_{\text{biaisé}} = \frac{1}{n} \sum_{i=1}^{n} (X_i - \hat{\mu})^2\]
Cependant, cet estimateur est biaisé. En effet, l’espérance de cet estimateur n’est pas égale à \(\sigma^2\) :
\[\mathbb{E}[\hat{\sigma}^2_{\text{biaisé}}] = \frac{n-1}{n} \sigma^2\]
Pour corriger ce biais, on peut utiliser un estimateur non biaisé de la variance. Cela se fait en divisant la somme des carrés par \(n - 1\) au lieu de \(n\). Ainsi, l’estimateur non biaisé de la variance est :
\[\hat{\sigma}^2_{\text{non biaisé}} = \frac{1}{n - 1} \sum_{i=1}^{n} (X_i - \hat{\mu})^2\]
Cet estimateur est non biaisé, et l’espérance de \(\hat{\sigma}^2_{\text{non biaisé}}\) est égale à la vraie variance de la population :
\[\mathbb{E}[\hat{\sigma}^2_{\text{non biaisé}}] = \sigma^2\]
Estimateur convergent
Un estimateur est dit convergent s’il converge en probabilité vers le paramètre à estimer : \[\hat{\theta}_n \xrightarrow{P} \theta\]
En pratique, tout estimateur sans biais et dont la variance tend vers 0 est convergent.
Estimateur optimal
La qualité d’un estimateur est mesurée à travers son erreur quadratique moyenne définie par : \[EQM(\hat{\theta}_n) = (b_n(\hat{\theta}, \theta))^2 + V(\hat{\theta}_n)\] Comme nous cherchons tout le temps (presque) des estimateurs sans biais, il reste à comparer les variances.
Un estimateur \(\widehat{\theta}_1\) est meilleur que \(\widehat{\theta}_2\) si : \[V(\widehat{\theta}_1) < V(\widehat{\theta}_2)\]
On définit la quantité d’information apportée par l’estimateur par
\[I(\hat{\theta}_n) = - \mathbb{E}_{\theta} \left( \left(\frac{\partial l(\theta ; X_{1:n})}{\partial \theta} \right)^2 \right),\] où \(l(\theta ; X_{1:n}) = \log \mathbb{P}_{X_{1:n}}(X_{1:n})\) est la log-vraisemblance de l’échantillon \(X_{1:n} = X_1, \cdots, X_n\).
L’inégalité de Cramér-Rao établit que la variance d’un estimateur ne peut pas aller en deçà d’un certain seuil :
\[\textrm{Var}(\hat{\theta}_n) \geqslant \frac{1}{I(\hat{\theta}_n)}.\] Un estimateur est optimal (ou efficace) si sa variance vérifie le cas d’égalité.
Construction d’un estimateur
Un estimateur est une valeur qu’on ne peut pas obtenir en théorie donc on essaye de l’estimer. Par exemple, on ne peut pas calculer l’espérence d’une série de données et donc pour essayer d’obtenir une valeur on calculer une estimation. On recours à plusieurs estimateurs tels que le maximum de vraisemblance ou bien la méthode des moments.
La méthode du maximum de vraisemblance est la plus souvent utilisé dans les modèles de prédiction.
La méthode du maximum de vraisemblance consiste à affecter \(𝜃\) la valeur qui maximise la probabilité d’observer \((𝑥_1, 𝑥_2, … , 𝑥_𝑛)\) lorsque l’aléa du vecteur \((𝑋_1, 𝑋_2, … , 𝑋_𝑛)\) tombe. Sans trop rentrer dans la théorie de la vraisemblance, nous allons présenter un algorithme en cinq étapes pour calculer cet estimateur :
Etape 1 : Calculer la fonction de vraisemblance
Dans le cas continu : \[L(\mathbf{x}, \theta) = \prod_{i=1}^{n} f(x_i)\]
Dans le cas discret : \[L(\mathbf{x}, \theta) = \prod_{i=1}^{n} P(X_i = x_i)\]
Etape 2 : Calculer le log-vraisemblance Il s’agit de calculer un maximum, ce qui revient à dériver. Il s’agit ici d’un produit de n facteurs, ce qui rend la dérivation assez coriace. La fonction logarithmique présente des propriétés assez sympas pour faciliter cette tâche.
Etape 3 : Calculer la dérivée de la log-vraisemblance
Etape 4 : Résoudre l’équation d’inconnue \(𝜽\)} \[\frac{\partial (\ln(L))}{\partial \theta} = 0 \Rightarrow \theta = \theta_0\]
Etape 5: Vérifier qu’il s’agit d’un maximum.
En s’assurant que : \[\frac{\partial^2 (\ln(L))}{\partial \theta^2} < 0\]
La méthode des moments consiste à égaliser les moments théoriques (espérance, variance) à leurs équivalents empiriques et à en dégager une estimation ponctuelle.
En pratique, il faut résoudre l’(les) équation(s) : \[\mathbb{E}(X) = \overline{X} \text{ et } \text{Var}(X) = S_n^2\] avec : \[\overline{X} = \frac{1}{n} \sum_{i=1}^{n} X_i \hspace{2cm} S_n^2 = \frac{1}{n} \sum_{i=1}^{n} (X_i - \overline{X})^2\]
Il existe une autre méthode d’estimateurs qu’est la méthode des moindres carrés ordinaires.
Lorsqu’il s’agit de prendre une mesure 𝜃 avec un appareil doté d’une imprécision \(𝜀\), alors le problème d’estimation peut s’écrire : \(𝑋 = 𝜃 + 𝜀\). La méthode des moindres-carrés ordinaires consiste à trouver le paramètre \(𝜃\) qui minimise la somme des carrées des erreurs : \[𝜃_{𝑀𝐶𝑂} = \arg\min \left( \sum_{i=0}^n \varepsilon_i^2 \right) = \arg\min \left( \sum_{i=0}^n (X_i - \theta)^2 \right)\]
Intervalles de confiance
Un intervalle de confiance [\(A\), \(B\)] de niveau \(1 - \alpha\) est un intervalle aléatoire qui a la probabilité \(1 - \alpha\) de contenir le paramètre à estimer \(\theta\). Formellement, on écrit : \(P (t_1 (\theta) \leqslant f(X_1, \ldots, X_n) \leqslant t_2 (\theta)) = P(A \leqslant \theta \leqslant B) = 1 - \alpha\)
Test d’hypothèses
Dans le cadre d’un test d’hypothèse, nous cherchons à faire valoir une hypothèse en dépit d’une autre, qui lui est contradictoire.
On appellera la première (celle dont le rejet à tort sera le plus préjudiciable) « Hypothèse nulle » et la deuxième « Hypothèse alternative ».
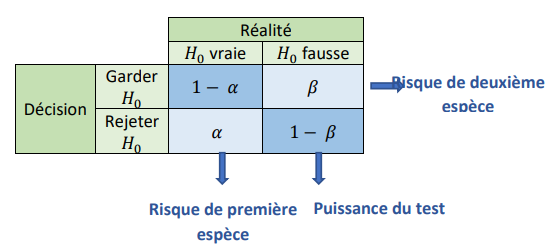
Les calculs qui se cachent derrière le choix de l’hypothèse à garder sont compliqués. Mais BONNE NOUVELLE, la machine fera tour à notre place. Il suffit juste de suivre correctement la méthode :
Etape 1 : Choisir judicieusement les hypothèses à évaluer et fixer le risque \(𝛼\)
Etape 2 : Choisir le test adapté à la procédure
Etape 3 : Rentrer la commande correspondante sur R et exécuter
Etape 4: Lire dans les sorties la p-value. si elle est supérieure à α on conserve l’hypothèse nulle H0. Si elle lui est inférieure, on rejette H0 et on accepte l’hypothèse alternative H1.
Construction d’intervalles de confiance
Les intervalles de confiance sont des outils essentiels en statistique pour estimer des paramètres inconnus tout en mesurant l’incertitude associée à cette estimation. Ci-dessous, vous trouverez un tableau présentant la construction des intervalles de confiance pour différents paramètres.
Statistiques descriptives univariées
La moyenne arithmétique d’une série de valeurs \(x_1, x_2, \ldots, x_n\) est donnée par : \[\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i\]
La médiane est la valeur qui sépare la série en deux parties égales. Pour une série ordonnée, si \(n\) est impair, la médiane est la valeur centrale. Si \(n\) est pair, c’est la moyenne des deux valeurs centrales.
La variance est une mesure de la dispersion des valeurs autour de la moyenne : \[\sigma_x^2 = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2\]
L’écart-type est la racine carrée de la variance : \[\sigma = \sqrt{\sigma_x^2}\]
Plus l’écart-type est grand, plus les données sont dispersées autour de la moyenne.
Les statistiques descriptives univariées sont essentielles pour résumer et comprendre les caractéristiques principales d’une seule variable. Elles sont largement utilisées en analyse de données pour obtenir une vue d’ensemble rapide et efficace. Elles permettent aussi d’identifier rapidement des valeurs extrêmes.
Statistiques descriptives bivariées
Définitions
Les nuages de points (ou diagrammes de dispersion) sont une méthode graphique utilisée pour observer la relation entre deux variables quantitatives. Chaque point du graphique représente une paire de valeurs \((x,y)\) pour ces deux variables. Ce type de graphique permet de visualiser des tendances, des corrélations (positives, négatives ou nulles), ainsi que la présence d’éventuelles anomalies ou valeurs aberrantes. Si les points semblent s’aligner le long d’une ligne droite, cela peut indiquer une relation linéaire entre les deux variables.
Les boxplots (ou boîtes à moustaches) sont un autre outil graphique, souvent utilisé pour représenter la distribution d’une variable quantitative en fonction d’une variable qualitative. Ils montrent la médiane, les quartiles, ainsi que les valeurs extrêmes ou aberrantes d’un jeu de données. Dans un boxplot, la boîte représente l’intervalle interquartile (de Q1 à Q3), la ligne médiane à l’intérieur de la boîte représente la médiane de la distribution, et les moustaches s’étendent jusqu’aux valeurs non aberrantes les plus extrêmes. Ces graphiques sont utiles pour comparer rapidement la dispersion et la symétrie des distributions entre différentes catégories d’une variable qualitative.
Economie
Concepts de base
Macroéconomie

La macroéconomie est l’étude économique d’un système ou de phénomènes à un niveau global de l’économie.
Microéconomie
La microéconomie se concentre sur l’observation et l’analyse des interactions à petite échelle.
Bien économique
“Chose utile à satisfaire un besoin, il faut que le bien soit disponible et en quantité limitée.
Un bien non économique est un bien qui s’obtient gratuitement, comme l’oxygène, contrairement à un bien économique qui s’obtient en payant.”
Agent économique
“Un agent économique est un individu ou un groupe d’individus constituant un centre de décision économique indépendant.”
Marché
“Le marché c’est une institution sociale qui permet l’échange entre l’offre et la demande.”
Asymétrie d’information
“L’asymétrie d’information concerne les situations où les agents d’un marché ne possèdent pas de la même information sur un produit que ce soit au sujet de ses qualités ou de ses défauts”
Externalité
L’externalité désigne la conséquence (positive ou négative) d’une activité d’un agent économique sur un autre, sans qu’aucun des deux ne reçoive ou ne paye une compensation pour cet effet.
Concurrence Pure et Parfaite
La CPP repose sur cinq fondements :
- L’Atomicité du marché
Existence d’un grand nombre d’agent économique sur le marché, à tel un point que ni l’offre ni la demande ne peut exercer une action quelconque sur la production et les prix ;
- L’Homogénéité des produits
La préférence d’un produit à un autre du point de vue de l’acheteur se fait uniquement selon son prix ;
- Libre entrée et sortie sur le marché
Aucune firme ne peut s’opposer à l’arrivée d’un concurrent sur le marché, tout le monde est libre de l’intégrer ;
- Libre circulation des facteurs de production
Les facteurs de production (capital et travail) doivent être libre de se déplacer librement sans obstacle d’une industrie à l’autre ;
- La transparence de l’information
Offreurs et demandeurs sont parfaitement conscient des caractéristiques et prix des produits.
Monopole
“Le monopole est une situation dans un marché où un vendeur fait face aux multitudes vendeurs.”
Segmentation de marché
“La segmentation de marché est un découpage du marché en groupes homogènes selon des critères spécifiques, que ce soit des critères démographiques ou bien géo-graphiques.”
Discrimination par les prix
“La discrimination par les prix est le pouvoir de pratiquer des prix différents pour un même produit, peut s’appliquer sur la quantité ou bien selon la segmentation du marché.”
Utilité
“L’utilité mesure le bien-être liée à la consommation d’un bien.”
Actualisation
“L’Actualisation est un calcul permettant de transformer une valeur future en une valeur présente.”
Que vaut aujourd’hui les X euros que j’aurais demain ?
\[V_a = \frac{V_f}{(1+i)^t}\]
\[V_a : Valeur\ Actuelle\]
\[V_f : Valeur\ future\]
\[i : Taux\ sans\ risque\\ \]
\[t : Temps\]
Problèmes macroéconomiques
Il existe 4 grands problèmes macroéconomiques :
Crises et récessions Ralentissement et/ou régression de l’activité économique ;
Inflations Augmentation générale et durable du niveau des prix entraînant une perte du pouvoir d’achat de la monnaie ;
Chômage Inactivité due au manque de travail ;
Problème de l’équilibre extérieur Quand les importations sont plus importantes que les exportations, la balance commerciale est déséquilibrée.
Rédaction d’une dissertation
“On tient tout d’abord à remercier l’enseignant chercheur (en Philosophie économique, Théories économiques de la justice, Redistribution des revenus, Economie sociale, Economie publique), monsieur Jean-Sébastien Gharbi pour cette rubrique d’aide à la dissertation.”

On pense souvent que la dissertation en économie est un exercice difficile et qui récompense mal le travail. C’est totalement faux. La dissertation est un exercice dans lequel il est facile d’obtenir la moyenne, et même (avec un peu d’entraînement) d’obtenir systématiquement de très bonnes notes. C’est un exercice relativement facile parce que c’est un exercice en très grande partie formel : tout est une question de méthode.
Faire une dissertation, c’est montrer que vous êtes capable d’utiliser et de réorganiser vos connaissances pour répondre à une question de manière argumentée (c’est-à-dire sous la forme d’un raisonnement). Autrement dit :
- Une dissertation n’est pas une question de cours.
La première chose à faire, c’est de différencier question de cours et dissertation (qui sont souvent confondues). Une question de cours demande simplement de réciter un cours. Si vous ne faites que réciter votre cours dans un exercice de dissertation, vous aurez une mauvaise note. Pourquoi ? Parce que l’exercice de dissertation suppose de montrer que vous êtes capable d’utiliser et de réorganiser vos connaissances (dans un temps limité) – pas seulement de réciter une leçon apprise plus ou moins par cœur. Comme la question de cours, la dissertation suppose donc que vous savez des choses sur le sujet, mais il est important de comprendre que la dissertation porte tout autant sur votre aptitude à organiser vos idées que sur vos connaissances.
- Dans une dissertation, la réponse donnée n’est pas importante !
Une dissertation consiste toujours à répondre à une question. Les étudiants pensent parfois qu’il y a une « bonne » réponse à la question posée – qu’il s’agirait de trouver. D’ailleurs, cela contribue à l’idée (fausse) que la dissertation est un exercice aléatoire : si vous ne trouvez pas la bonne réponse, vous avez perdu. Cela aussi est faux : il n’y a (en général) pas de « bonne » réponse à la question posée par la dissertation. L’exercice de dissertation vient de la philosophie. Pensez-vous sérieusement que l’on puisse demander à un étudiant (ou à un professeur, d’ailleurs) de régler de façon définitive un débat philosophique qui a donné lieu à des controverses pendant des siècles en trois, quatre ou même sept heures ? La réponse évidente est « non ».
- Dans une dissertation, le plus important c’est l’argumentation !
Si on ne s’intéresse pas à la réponse donnée. C’est tout simplement, parce que ce qui intéresse votre lecteur, c’est la manière dont vous répondez : votre aptitude à utiliser vos connaissances de manière argumentative pour défendre une conclusion. Sur le principe, il serait donc possible de défendre une conclusion choquante ou même offensante dans une dissertation, pour la bonne raison qu’on n’évalue pas la réponse que vous donnez, mais la manière dont vous amenez votre réponse. Votre réponse, à la limite, on ne s’y intéresse pas. Une fois cela dit, il est assez évident qu’il est beaucoup plus facile de défendre une position modérée et consensuelle, qu’une position offensante pour de nombreuses personnes. C’est la raison pour laquelle, il n’est pas du tout conseillé de chercher la provocation gratuite dans une dissertation.
Comment on fait une dissertation ?

Analyse du sujet
L’analyse du sujet est la première étape de la dissertation et l’une des plus importantes. Une dissertation se présente sous la forme d’un sujet. Il faut isoler la ou les deux notions principales du sujet.
Il y a quatre grands types de sujets : les sujets ne contenant qu’une seule notion (ex : « Les discriminations en France »), les couples de notions (ex : « Capitalisme et démocratie »), les citations (ex : « Le système de production capitaliste est une démocratie économique dans laquelle chaque sou donne un droit de vote. Les consommateurs constituent le peuple souverain », Ludwig von Mises) ou une question (ex : « La croissance économique s’oppose-t-elle à la préservation de l’environnement ? »).
Dans tous les cas, l’objectif est d’arriver à une question (donc les sujets les plus simples à traiter à ce stade, ce sont les questions : ils vous donnent immédiatement le problème à traiter). Mais la première chose à faire (même quand on a déjà la question), c’est de trouver le couple de notions impliquées dans le sujet. Souvent, c’est absolument évident, mais parfois il faut un peu chercher.
Il faut éviter à tout prix de faire un exposé quand on attend de vous une dissertation. Un hors-sujet, c’est de ne pas traiter le bon sujet. Si vous répondez de manière factuelle à un sujet de dissertation, vous faites pire : vous faites un hors-exercice.
Recherche des idées
Une fois qu’on a identifié un couple de notions, il faut (au brouillon) essayer de faire la liste des éléments du cours qui relient les deux notions. Il est important de ne noter que les éléments qui relient les deux notions (pour ne pas risquer de se perdre dans des éléments qui concernent seulement une seule des deux notions). Sur chacune des notions que vous aurez à traiter en dissertation, on a écrit des livres entiers. Il est impossible de tout dire dessus dans une dissertation. On se limite donc à ce qui relie les deux notions de notre sujet. Évidemment, si un élément pertinent vous vient en tête et qu’il ne se trouve pas dans votre cours, n’hésitez pas à le noter. Si cet élément peut être utilisé dans votre raisonnement, même comme exemple, ce sera un plus indiscutable.
Dans un premier temps, on note tout ce qui se présente à l’esprit. Ce n’est que dans un deuxième temps, quand on a un certain nombre d’éléments que l’on se pose la question : « Est-ce qu’il y a une manière qui saute aux yeux de relier tous ces éléments en répondant à la question (si elle a été posée de manière directe) ou pour répondre à une question comprenant le couple de notions (si la question n’a pas été formulée dans le sujet) ? ». Si la réponse est positive, on a trouvé la question qui structurera notre devoir. Si ce n’est pas le cas, il faut essayer de trouver une question qui relie le plus grand nombre des éléments que l’on a noté sur son brouillon – et donc laisser de côté les éléments qui ne servent pas. Il arrive souvent qu’une partie des éléments que l’on note sur son brouillon ne soit pas utilisée dans le devoir. Bref, si notre sujet est un couple de notions ou une citation, il faut que l’on arrive à une question. Évidemment, quand notre sujet est déjà une question, on n’a pas autant de marge de manœuvre, mais en vérité, si on vous pose une question précise, c’est que vous avez les éléments pour y répondre dans le cours (donc la différence n’est pas très importante).
Mise en évidence d’un problème
Puisqu’elle ne doit pas être une question de fait, la question qui relie le plus d’éléments possibles parmi ceux qui associent les deux notions dans votre cours doit être une question conceptuelle. Pour le dire autrement, cette question doit être un problème (on parle souvent de « problématique » pour désigner ce problème dans le cadre d’une dissertation). Qu’est-ce qu’un problème ? C’est une question qui met en tension deux concepts et qui analyse les différents aspects de leur relation (conceptuelle).
Souvent les étudiants ont peur de ne pas trouver le « bon » problème. Pourtant, si on suit la méthode de dissertation, il n’y a pas de risque de se tromper. En effet, on ne doit pas choisir un problème d’abord (sans savoir si on a de quoi le traiter) et le traiter ensuite. Vous aurez noté qu’on procède exactement dans le sens inverse : on voit à quelle question on peut répondre avec les éléments qu’on a sur son brouillon et on pose précisément la question à laquelle on sait qu’on peut répondre.
Construction du plan
Pour la même raison qu’au-dessus, la construction du plan ne doit pas être très difficile : il s’agit de rassembler les différents éléments qui permettent de répondre à la question (au problème que l’on va poser) de façon à y apporter une réponse.
On va apporter la réponse que les éléments disponibles nous permettent d’atteindre. Il y a une seule contrainte : votre plan doit être suffisamment détaillé. Comme l’objectif de la dissertation, c’est de montrer que vous êtes capable d’utiliser et de réorganiser vos connaissances. Si vous ne faites que deux parties sans sous-parties à l’intérieur (il n’y aurait donc qu’une seule articulation logique), on trouvera que vous n’avez pas assez structuré votre devoir. Le découpage minimal, c’est d’avoir quatre éléments (en général, on fait deux grandes parties avec deux sous-parties chacune, donc on a trois articulations).
Vos parties et vos sous-parties doivent correspondre à des étapes de votre raisonnement (on dit souvent qu’il faut une idée par sous-partie), donc votre plan doit donner la structure du raisonnement grâce auquel vous allez répondre à la question posée. Le plan (qui est annoncé à la fin de l’introduction et qui doit être apparent dans le devoir, nous reviendrons sur ce point un peu plus loin) doit permettre de comprendre la structure de votre devoir d’un coup d’œil – simplement en lisant les titres.
Un élément qui permet de savoir si votre plan est bon, c’est de se demander si à la fin de la première partie, on est arrivé à un état de la réflexion différent de celui de la fin de l’introduction.
Qu’est-ce que la première partie a permis de comprendre ? Et est-ce que la seconde partie apporte quelque chose d’autre ? Si chaque partie représente une étape dans un raisonnement et que votre devoir complet est donc un raisonnement, votre plan est forcément bon : vu que c’est précisément ce qu’on attend de vous.
Il ne faut jamais faire deux sous-parties dans une partie sous la forme d’une seule phrase coupée par des points de suspension (ex : « A) L’organisation scientifique du travail a permis la croissance des trente glorieuses… », « B) mais, elle a aussi eu des conséquences négatives, notamment sur le plan social »). En effet, cela revient à pointer du doigt que vous opérez une coupure arbitraire (donc que vous n’articulez pas de manière assez nette les différentes parties de votre devoir). Sur le principe, les deux sous-parties sont reliées par les points de suspension et donc ne forment qu’une partie sans coupure. Préférez toujours les titres qui se succèdent sans être grammaticalement liés les uns aux autres. Dans l’exemple ci-dessus, il suffit de faire deux phrases pour découper les deux idées. Si on ne peut pas couper grammaticalement les deux titres, c’est la preuve que l’articulation pose problème.
Dans l’idéal, un plan est équilibré : chaque partie comprend le même nombre de sous-parties que l’autre et elles font à peu près la même longueur. Et si vous faites plus de sous-parties dans une partie que dans l’autre, il faut que les sous-parties soient un peu plus longues dans la partie qui contient moins de sous-parties. Remarquez que si vous faites un plan avec deux parties, deux sous-parties, ce dernier problème ne se pose pas.
Un point important et souvent totalement négligé par les étudiants : même quand c’est tentant, on ne fait jamais de plan centré sur les auteurs. Un plan par auteurs conduit très souvent à suivre l’ordre chronologique et à présenter les positions des auteurs sans les confronter réellement les unes aux autres . Ce qui doit structurer le plan, ce sont les concepts (c’est-à-dire les notions qui nous avaient permis de construire le problème à résoudre).
En réalité, il n’est pas rare qu’on suive plus ou moins l’ordre chronologie, mais il est essentiel de se focaliser sur les concepts, et pas sur les auteurs. Pourquoi ? Parce que l’enchaînement ou l’opposition de concepts constitue un raisonnement (ce que vous devez faire !), alors que l’enchaînement ou l’opposition d’auteurs constitue un exposé (ce que vous ne devez pas faire !). En réalité, c’est assez facile à faire il suffit de s’interdire de mentionner le nom des auteurs dans les titres de partie ou de sous-partie.
Vu que l’objectif du plan, c’est de répondre à une question qui met les deux notions du sujet en relation, les parties (ou les sous-parties) qui se focalisent sur une seule des deux notions sont à éviter à tout prix : elles sont simplement hors-sujet. Sur un sujet comme « capitalisme et démocratie », le plan « première partie : capitalisme », « deuxième partie : démocratie » est parmi les pires possibles.
Jusqu’à présent, nous n’avons encore rien écrit sur la copie elle-même. Nous n’avons travaillé que sur le brouillon. Nous avons deux notions clés, un problème et un plan. Ce sont les éléments fondamentaux du devoir. Il faut à présent passer à la rédaction. Nous allons nous intéresser d’abord à l’introduction.
La rédaction
(Introduction, Conclusion, Développement)
L’introduction est la partie la plus importante de la dissertation. Elle permet de savoir pourquoi le problème se pose, comment il se pose et comment il va être résolu. A quoi sert l’introduction ?
Le rôle de l’introduction, sa raison d’être, c’est de construire et d’énoncer le problème (la problématique) auquel le reste du devoir va répondre. Il ne suffit donc pas de poser la question (pour cela deux lignes suffiraient) et de commencer le développement. L’introduction, comme son nom le dit très bien, va introduire le problème, c’est-à-dire qu’elle va nous y amener, rapidement, certes, mais en plusieurs étapes très codifiées.
Une introduction de dissertation comprend obligatoirement (au minimum) cinq éléments : une accroche, une définition des termes du sujets, la construction du problème, l’énoncé du problème et l’annonce du plan. Comme une introduction de dissertation fait entre 20 lignes et une page et demie (grand maximum), il faut être efficace.
- L’accroche
Une introduction de dissertation suit des règles assez rigides. Elle commence toujours par une accroche.
Une « accroche », c’est une phrase ou deux qui vont contenir la ou les deux notion(s) du sujet. Son rôle est d’amener par étapes le lecteur vers la question que vous allez poser. Elle sert donc d’introduction à l’introduction. Une accroche peut être une citation (il y en a toujours dans un cours) ou un fait récent (le chômage a-t-il baissé récemment ? Un candidat à l’élection présidentielle a-t-il dit qu’il fallait juger sa politique en fonction de son impact sur le niveau de chômage ?). Si on n’a pas de citation ou de fait relevant de l’actualité, on peut amener le sujet de façon plus habituelle.
Il est important d’éviter un certain nombre de formules toutes faites et souvent utilisées comme « De tous temps… », « De tous temps, les hommes… » ou encore les affirmations très générales (et que vous ne justifierez pas) comme : « Le chômage est un phénomène économique important, c’est pourquoi il faut l’étudier ». Le défaut de tous ces débuts d’accroche, c’est qu’ils peuvent servir pour n’importe quel sujet et que cela se voit.
On met une accroche parce que cela permet de mentionner les termes du sujet sans commencer directement par une définition – ce qui constitue l’étape suivante.
- Définition des termes du sujet
L’accroche a introduit les notions, mais sans les définir – comme si tout le monde savait précisément de quoi il s’agit (ce qui n’est pas si surprenant, on ne passe pas son temps à définir tous les mots qu’on utilise). Mais, pour utiliser les deux notions du sujet de façon un peu plus précise, il faut les définir. Les définitions que l’on va donner dans une introduction n’ont pas pour objectif de définir les notions de manière exhaustive ou dans l’absolu. Elles doivent permettre de comprendre le lien (ou l’opposition) entre les deux notions et orienter l’introduction de façon à ce que l’on puisse construire le problème – avant de l’énoncer (autrement dit, elles doivent ouvrir la voie aux deux étapes suivantes de l’introduction).
Du coup, les définitions que l’on va donner vont dépendre du problème que l’on souhaite atteindre.
- Construction du problème
Comme on sait à quelle question on doit arriver (que cette question nous ait été donnée par le sujet ou que ce soit la question à laquelle on est le mieux armé pour apporter une réponse), il ne va pas être difficile de passer des définitions au problème. Cela suppose juste de montrer qu’avec les définitions que l’on vient de donner, il y a une question se pose avec force.
Encore une fois, cela peut sembler très artificiel (et ça l’est). Toutefois, l’intérêt de cet aspect artificiel, c’est qu’il nous garantit que l’on ne va pas se perdre en chemin. Quand on fait une dissertation, on ne cherche pas son chemin : on sait où on va et on ne fait qu’expliquer pourquoi on y va. Le sujet que l’on construit ne tombe pas du ciel, il vient de notre cours. Les définitions ne tombent pas du ciel, elles donnent les éléments qui vont nous permettre de poser la question à laquelle on sait déjà comment on va répondre. Bref, l’étape de construction du problème est importante parce qu’elle montre que vous avez des aptitudes pour vous faire comprendre à l’écrit (et il ne faut surtout pas la négliger), mais elle n’est pas une étape difficile ou magique.
Vous pourriez être surpris que l’on construise le sujet, alors qu’il nous est parfois donné sous forme de question (dans les autres cas, on comprend mieux pourquoi il est nécessaire de construire le problème). En fait, c’est une manière de montrer que vous êtes capable de vous approprier le sujet. Vous ne traitez pas le sujet parce qu’on vous l’a donné (même si vous c’est une des raisons pour lesquelles vous faites une dissertation), mais parce que vous comprenez pourquoi la question se pose. Et comment mieux montrer qu’on comprend un problème qu’en montrant en quoi il est problématique ? Autrement dit, même quand votre sujet a la forme d’une question, vous devez passer par l’étape de construction du sujet dans l’introduction.
- Enoncé du problème
L’énoncé du problème doit prendre la forme d’une question. Il est le point final de l’étape juste précédente. Une fois qu’on a les éléments qui permettent de comprendre que le problème se pose, il faut explicitement exprimer le problème lui-même. On exprime toujours le problème sous la forme d’une question (parce que c’est une manière de montrer qu’il appelle une réponse) et d’une question unique. Poser deux, trois ou quatre questions ce serait soit redire plusieurs fois la même chose (et si votre première question est claire, c’est inutile), soit poser (volontairement ou pas) plusieurs questions différentes. Or, vous ne pourrez pas répondre convenablement et dans les règles de la dissertation à plusieurs questions en un seul devoir. Vous devrez donc choisir entre ne pas traiter certaines des questions que vous avez explicitement posées (et dans ce cas pourquoi les poser explicitement) ou essayer de les traiter toutes (ce qui vous conduira à un devoir dont la ligne directrice sera au mieux difficile à suivre, au pire inexistante). Si on se rappelle du côté formel et rhétorique d’une dissertation, on comprend qu’il ne faut poser qu’une seule question : celle à laquelle vous apportez une réponse.
Lorsque le sujet est une question, faut-il répéter mot pour mot le sujet comme énoncé du problème ? Il y a deux écoles : la première dit qu’il faut reformuler la question pour montrer que vous la comprenez. Ainsi un sujet comme « Les dépenses publiques permettent-elles de réduire le chômage ? », on pourrait proposer une problématique comme « les dépenses publiques sont-elles efficaces à court et à long terme pour lutter contre le chômage ? ».
Si vous faites correctement votre travail de définition des termes et de construction du sujet (dans les deux étapes précédentes), je pense qu’aucun correcteur ne vous reprochera de reprendre le sujet mot pour mot dans votre énoncé du problème. Ce qui pose problème pour les partisans de la première façon de faire, c’est quand on peut se demander si l’étudiant comprend que la question qu’il pose est un problème conceptuel, c’est-à-dire qui vient d’une tension entre deux notions. Dans une introduction qui remplit correctement son rôle de construction du problème, le fait de répéter le sujet mot pour mot n’est pas un souci.
- Annonce du plan
Une introduction doit toujours se terminer par une annonce du plan (ce n’est pas une option, c’est une obligation). L’annonce de plan dit à votre lecteur comment vous allez répondre au problème que vous venez de poser. Dans une dissertation, on ne joue pas sur le suspens. On ne cherche pas à surprendre son correcteur. Il faut donc annoncer le plan de manière à ce qu’il comprenne que vous allez répondre au problème posé par un raisonnement et qu’il comprenne aussi quels vont être les principales étapes de votre raisonnement (c’est-à-dire de votre devoir).
Vous allez donc annoncer vos (deux ou trois) grandes parties. Il est conseillé fortement d’utiliser les formules (un peu lourdes en termes de style, mais très claires) « dans une première partie, nous montrerons que… », puis « dans une deuxième partie, nous verrons que … ». Quand vous ne le faites pas, il arrive trop souvent que votre lecteur ne sache pas si vous allez faire formellement deux ou trois parties – pour peu que vous utilisiez des mots comme « et », « puis » ou « ensuite », qui peuvent aussi bien marquer des étapes à l’intérieur d’une grande partie que le passage d’une partie à une autre.
La conclusion
Vous pourriez être surpris de voir la conclusion arriver aussi tôt dans le devoir. La raison, c’est qu’il est inconcevable de ne pas répondre à la question posée en introduction – si vous ne répondez pas le devoir n’aura, littéralement, servi à rien. Or, il est évident qu’en partiel, on est souvent pris par le temps. On rédige donc la conclusion juste après avoir rédigé l’introduction au brouillon (on la rédige aussi au brouillon, d’ailleurs). Comme ça si on est pris par le temps, on pourra recopier la conclusion déjà prête avant de rendre le devoir. S’il faut couper quelque chose en raison du temps limité de l’épreuve, il vaut mieux couper un bout du développement que rendre une dissertation sans conclusion.
La première phrase de votre conclusion doit apporter la réponse à la question que vous avez posée en introduction. Elle doit le faire de façon absolument claire et donc il est conseillé de reprendre exactement la question en la tournant en une phrase affirmative ou en une phrase négative selon votre réponse. Le rôle de la conclusion, c’est de répondre à la question. Il ne faut pas qu’on relise la conclusion en se demandant quelle était la réponse – et même en se demandant si une réponse a été donnée. Cela ne vous empêche pas de donner une réponse nuancée, mais il faut une réponse claire.
Une conclusion de dissertation ne résume pas le devoir (on vient de le lire, c’est tout à fait inutile). Une conclusion n’introduit jamais un élément qui n’a pas été abordé dans le devoir, mais qui aurait pu y être discuté. Si jamais votre correcteur n’a pas vu que vous avez oublié de parler de quelque chose d’important, vous n’allez tout de même pas lui dire qu’il manque quelque chose dans votre devoir (chacun son boulot). La dissertation est un exercice de rhétorique, votre objectif, c’est de convaincre votre lecteur : ce n’est pas à vous de dire qu’il manque quelque chose, même si vous le savez.
On conseille parfois de finir sa dissertation sur une ouverture. Une ouverture est un nouveau problème qui se pose une fois que vous avez répondu au problème de votre devoir. Cela revient à suggérer une autre dissertation possible une fois qu’on considère votre réponse comme acceptée. Trop souvent, les étudiants finissent leurs devoirs de manière particulièrement maladroite parce qu’ils ne comprennent pas ce qu’est une ouverture. Mon conseil est d’éviter de faire une ouverture, au moins au début : ce n’est pas une obligation et cela peut donner une très mauvaise impression finale.
La rédaction du devoir
Une fois tout cela fait, on prend sa copie (totalement vierge à ce moment) et on commence à écrire dessus : on recopie l’introduction, on rédige le développement directement sur la copie (on ne rédige jamais son développement sur le brouillon, cela prend beaucoup trop de temps à recopier). Le développement du devoir doit contenir des titres apparents pour les parties et les sous-parties. Cela signifie que le titre de votre grande partie est marqué dans votre copie (précédé d’un « I) ») et qu’il est isolé du texte et souligné. Bref, on doit pouvoir voir apparaître d’un coup d’œil votre plan en survolant votre copie du regard.
Comme dit juste au-dessus, si on manque de temps, on coupe une partie du développement et on recopie la conclusion qui se trouve sur le brouillon. Attention : si vous ne rédigez pas tout le développement, mettez tout de même le plan apparent pour les parties et sous-parties non développées. C’est précisément parce qu’on a une idée de ce que vous auriez écrit qu’il est possible (en cas de gros manque de temps) de ne pas rédiger tout le développement. Si vous ne détaillez pas votre plan, c’est la trame de votre raisonnement qui manque et c’est beaucoup plus ennuyeux. Si vous ne pouvez pas rédiger tout le développement, je vous conseille de mettre des éléments que vous auriez utilisé sous forme de liste de tirets (en plus des titres apparents qui sont obligatoires).