10 bases de données orientées machine learning
Bien que leurs approches et leurs capacités diffèrent, de nombreuses bases de données permettent de créer des modèles d’apprentissage automatique pour exploiter et donner du sens à des mines d’informations. Aux côtés des mastodontes Amazon, Google, Oracle et Microsoft des plateformes comme BlazingSQL, Brytlyt et Kinetica sortent du lot.
")
Dans un article d’octobre 2022 intitulé Comment choisir une plateforme d’apprentissage automatique cloud, le premier conseil de Martin Heller pour le choix d’une plateforme était le suivant : « Soyez proche de vos données ». Garder le code près des données est nécessaire pour maintenir une faible latence, car la vitesse de la lumière limite les vitesses de transmission. Après tout, le machine learning (ML) - en particulier le deep learning - a tendance à parcourir toutes vos données plusieurs fois. L’idéal, pour les très grands ensembles de données, est de construire le modèle là où les données résident déjà, de sorte qu’aucune transmission massive de données ne soit nécessaire. Plusieurs bases de données le permettent dans une certaine mesure. La question suivante est naturellement : quelles bases de données prennent en charge le ML interne, et comment le font-elles ? Voici un tour d’horizon de ces bases de données par ordre alphabétique.
Amazon Redshift
Amazon Redshift est un service managé d’entrepôt de données à l’échelle du pétaoctet, conçu pour rendre simple et rentable l’analyse de toutes les données à l’aide d’outils de veille stratégique existants. Il est optimisé pour des ensembles de données allant de quelques centaines de gigaoctets à un pétaoctet ou plus et coûte moins de 1 000 $ par téraoctet et par an. Redshift ML est conçu pour permettre aux utilisateurs de SQL de créer, former et déployer facilement des modèles de ML à l’aide de commandes SQL. CREATE MODEL de Redshift SQL définit par exemple les données à utiliser pour la formation et la colonne cible, puis les transmet à SageMaker Autopilot pour la formation via un bucket Amazon S3 chiffré dans la même zone.
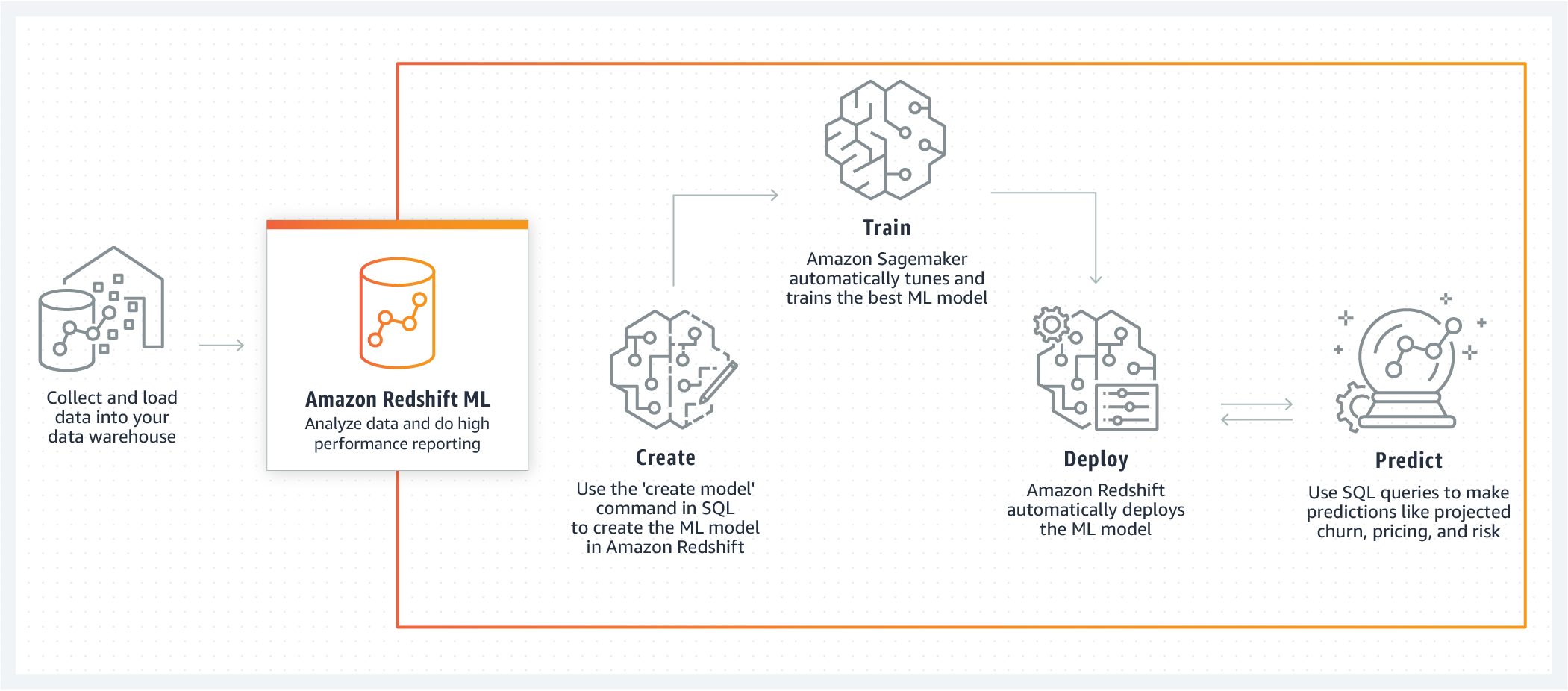
Fonctionnement de Redshift ML. (Crédit : AWS)
Après l’entraînement AutoML, Redshift ML compile le meilleur modèle et l’enregistre en tant que fonction SQL de prédiction dans votre cluster Redshift. Vous pouvez ensuite invoquer le modèle pour l’inférence en appelant la fonction de prédiction dans une instruction SELECT. En résumé, Redshift ML utilise SageMaker Autopilot pour créer automatiquement des modèles de prédiction à partir des données que vous spécifiez via une instruction SQL, qui sont extraites dans un bucket S3. La meilleure fonction de prédiction trouvée est enregistrée dans le cluster Redshift.
BlazingSQL
BlazingSQL est un moteur SQL accéléré par le GPU construit sur l’écosystème RAPIDS ; il existe sous forme de projet open source et de service payant. RAPIDS est une suite de bibliothèques logicielles et d’API open source, incubée par Nvidia, qui utilise CUDA et est basée sur le format de mémoire en colonnes Apache Arrow. CuDF, qui fait partie de RAPIDS, est une bibliothèque GPU DataFrame de type Pandas permettant de charger, de joindre, d’agréger, de filtrer et de manipuler des données. Dask, également open source, apporte de la mise à l’échelle des paquets Python sur plusieurs machines. Dask peut distribuer les données et les calculs sur plusieurs GPU, soit dans le même système, soit dans un cluster multi-nœuds. Dask s’intègre à RAPIDS cuDF, XGBoost et RAPIDS cuML pour l’analyse de données et l’apprentissage automatique accélérés par le GPU.
Ainsi, BlazingSQL peut exécuter des requêtes accélérées par le GPU sur des data lake dans Amazon S3, transmettre les DataFrames résultants à cuDF pour la manipulation des données, et enfin effectuer l’apprentissage automatique avec RAPIDS XGBoost et cuML, et l’apprentissage profond avec PyTorch et TensorFlow.
Brytlyt
Brytlyt est une plateforme basée sur un navigateur qui permet de traiter de l’IA dans une base de données avec des capacités de deep learning. Brytlyt combine une base de données PostgreSQL, PyTorch, Jupyter Notebooks, Scikit-learn, NumPy, Pandas et MLflow en une seule plateforme serverless qui sert de trois produits accélérés par GPU : une base de données, un outil de visualisation de données et un outil de science des données qui utilise des notebooks. Brytlyt se connecte à tout produit disposant d’un connecteur PostgreSQL, y compris les outils de BI tels que Tableau, et Python. Il supporte le chargement et l’ingestion de données à partir de fichiers de données externes tels que les CSV et à partir de sources de données SQL externes supportées par les wrappers de données étrangères (FDW) de PostgreSQL. Parmi ces dernières, citons Snowflake, Microsoft SQL Server, Google Cloud BigQuery, Databricks, Amazon Redshift et Amazon Athena.
En tant que base de données GPU avec traitement parallèle des jointures, Brytlyt peut traiter des milliards de lignes de données en quelques secondes. Brytlyt a des applications dans les télécommunications, le commerce de détail, le pétrole et le gaz, la finance, la logistique, l’ADN et la génomique. Avec PyTorch et Scikit-learn intégrés, Brytlyt peut supporter à la fois le deep learning et les modèles simples de ML fonctionnant en interne contre ses données. La prise en charge des GPU et le traitement parallèle signifient que toutes les opérations sont relativement rapides, même si l’entraînement de modèles d’apprentissage profond complexes sur des milliards de lignes prendra bien sûr un certain temps.
Google Cloud BigQuery
BigQuery est le datawarehouse infoféré de Google Cloud, à l’échelle du pétaoctet, pour exécuter des analyses sur de grandes quantités de données en temps quasi réel. BigQuery ML est utilisé pour créer et exécuter des modèles de ML dans BigQuery à l’aide de requêtes SQL. Ce data warehouse prend en charge la régression linéaire pour les prévisions, la régression logistique binaire et multi-classes pour la classification, le clustering K-means pour la segmentation des données, la factorisation matricielle pour la création de systèmes de recommandation de produits, les séries temporelles pour les prévisions de séries temporelles, y compris les anomalies, la saisonnalité et les jours fériés, les modèles de classification et de régression XGBoost, les réseaux neuronaux profonds basés sur TensorFlow pour les modèles de classification et de régression, les tableaux AutoML et l’importation de modèles TensorFlow.
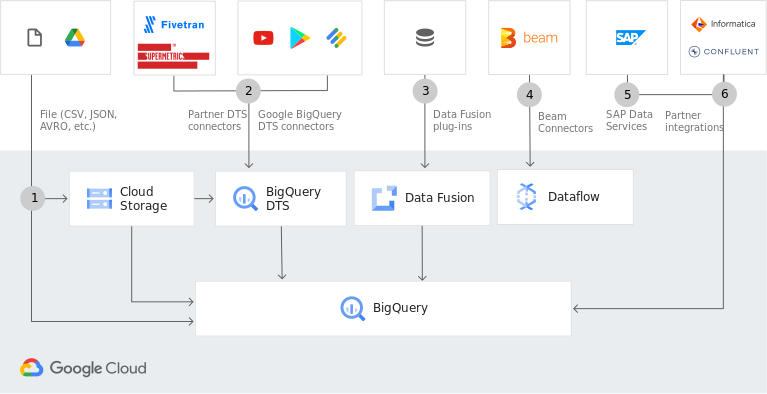
Google propose de faciliter les analyses en rassemblant les données provenant de plusieurs sources dans BigQuery. (Crédit : Google)
Vous pouvez utiliser un modèle avec des données provenant de plusieurs ensembles de données BigQuery pour l’entraînement et pour la prédiction. BigQuery ML n’extrait pas les données de l’entrepôt de données. Vous pouvez effectuer une ingénierie des fonctionnalités avec BigQuery ML en utilisant la clause TRANSFORM dans votre instruction CREATE MODEL. Selon Martin Heller, BigQuery ML apporte une grande partie de la puissance de Google Cloud Machine Learning dans l’entrepôt de données BigQuery avec la syntaxe SQL, sans extraire les données de l’entrepôt de données.
IBM Db2 Warehouse
IBM Db2 Warehouse on Cloud est un service de cloud public managé. Il est possible de configurer cet environnement sur site avec son propre matériel ou dans un cloud privé. En tant qu’entrepôt de données, il comprend des fonctionnalités telles que le traitement des données en mémoire et les tableaux en colonnes pour le traitement analytique en ligne. Sa technologie Netezza fournit un ensemble robuste d’analyses conçues pour amener efficacement la requête aux données. Une gamme de bibliothèques et de fonctions vous aide à obtenir les informations précises dont on peut avoir besoin.
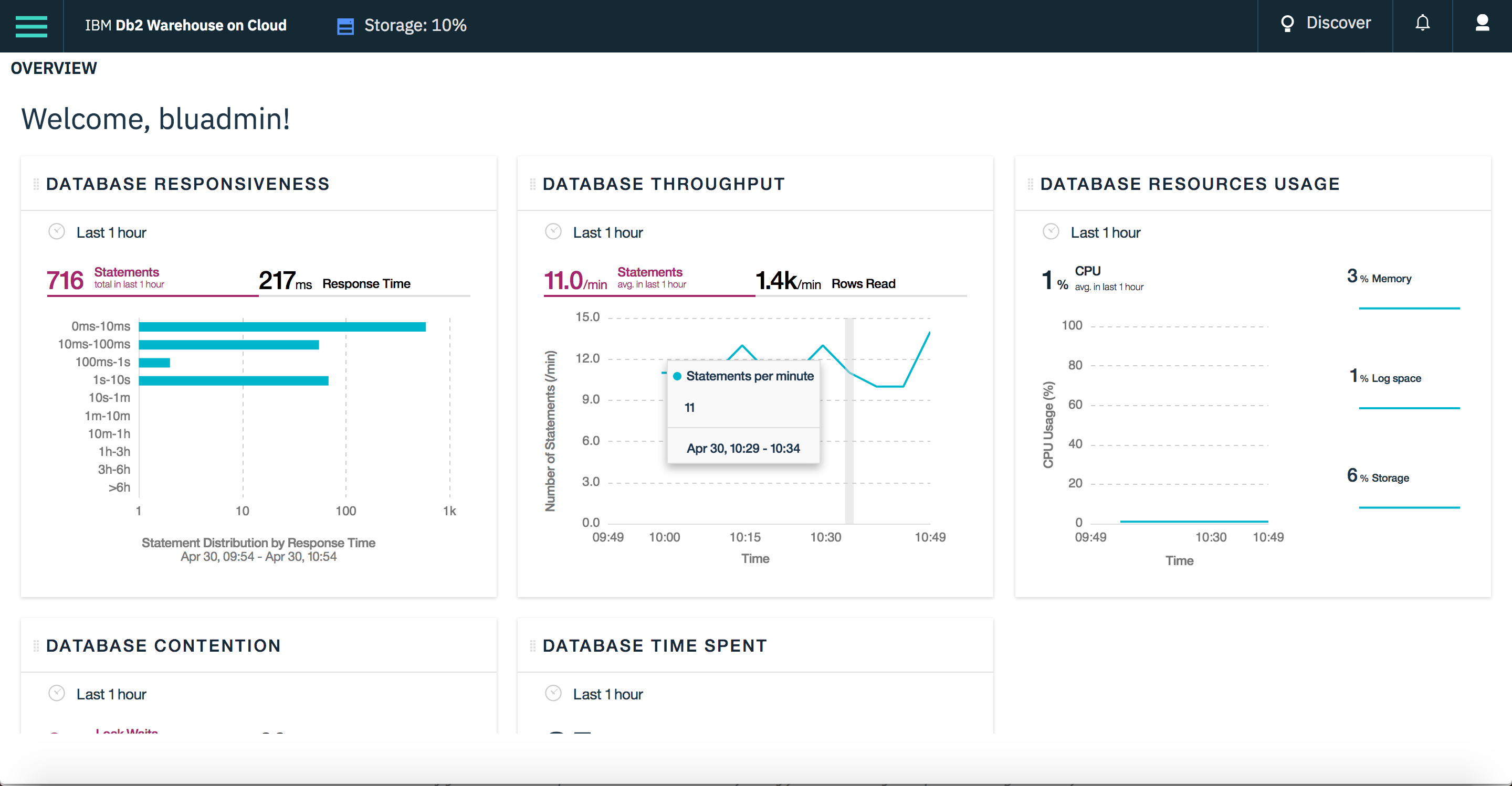
Obtenez un aperçu rapide de votre historique d’utilisation du stockage et de l’activité de chargement à l’aide du tableau de bord de la console Web. (Crédit : IBM)
Db2 Warehouse prend en charge le ML dans la base de données en Python, R et SQL. Le module IDAX contient des procédures analytiques stockées, notamment l’analyse de la variance, les règles d’association, la transformation des données, les arbres de décision, les mesures de diagnostic, la discrétisation et les moments, le regroupement K-means, les voisins les plus proches, la régression linéaire, la gestion des métadonnées, la classification naïve Bayes, l’analyse en composantes principales, les distributions de probabilités, l’échantillonnage aléatoire, les arbres de régression, les modèles et règles séquentiels, ainsi que les statistiques paramétriques et non paramétriques.
Kinetica
Kinetica Streaming Data Warehouse combine l’analyse de données historiques et en continu avec l’intelligence de localisation et l’IA dans une seule plateforme, le tout accessible via API et SQL. Kinetica est une base de données très rapide, distribuée, en colonnes, privilégiant la mémoire et accélérée par les GPU, avec des fonctionnalités de filtrage, de visualisation et d’agrégation.
Kinetica intègre des modèles et des algorithmes d’apprentissage automatique avec vos données pour une analyse prédictive en temps réel à l’échelle. Il vous permet de rationaliser vos pipelines de données et le cycle de vie de vos analyses, modèles d’apprentissage automatique et ingénierie des données, et de calculer des fonctionnalités avec le streaming. Kinetica fournit une solution de cycle de vie complet pour l’apprentissage automatique accéléré par les GPU : des carnets Jupyter gérés, l’entraînement des modèles via RAPIDS, et le déploiement et l’inférence automatisés des modèles dans la plateforme Kinetica. Il s’agit d’une solution complète de cycle de vie dans la base de données pour le ML accéléré par les GPU, et peut calculer des caractéristiques à partir de données en continu.
Microsoft SQL Server
Les services d’apprentissage automatique de Microsoft SQL Server prennent en charge R, Python, Java, la commande T-SQL PREDICT et la procédure stockée rx_Predict dans le SGBDR SQL Server, et SparkML dans les grappes de données Big Data de SQL Server. Dans les langages R et Python, Microsoft inclut plusieurs paquets et bibliothèques pour le ML. Vous pouvez stocker vos modèles formés dans la base de données ou en externe. Azure SQL Managed Instance prend en charge Machine Learning Services for Python et R en preview.
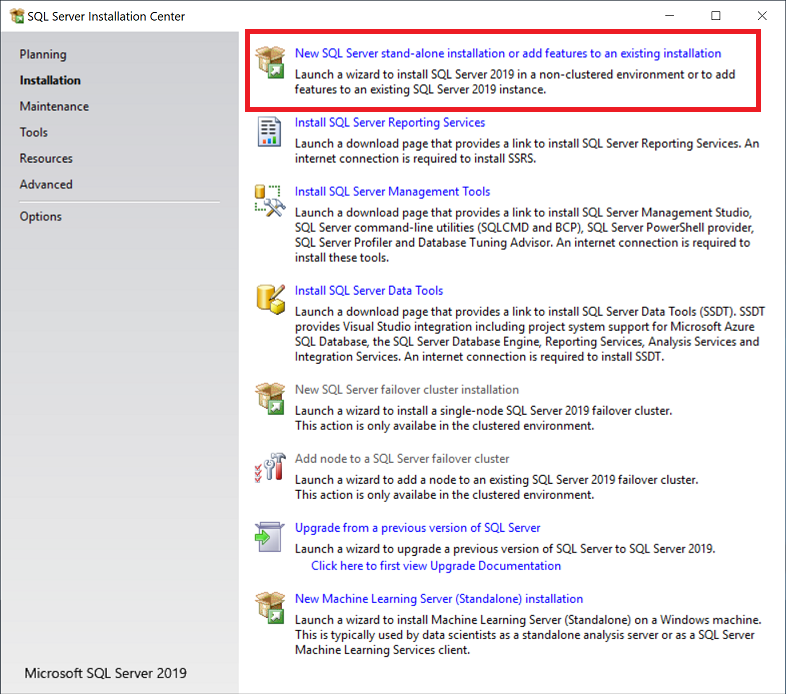
Pour lancer l’installation, il suffit de démarrer l’assistant de configuration de SQL Server, puis dans l’onglet Installation, sélectionner Nouvelle installation autonome de SQL Server ou ajouter des fonctionnalités à une installation existante. (Crédit : Microsoft)
Microsoft R dispose d’extensions qui lui permettent de traiter les données à partir du disque ainsi qu’en mémoire. SQL Server fournit un cadre d’extension pour que le code R, Python et Java puisse utiliser les données et les fonctions de SQL Server. Les clusters Big Data de SQL Server exécutent SQL Server, Spark et HDFS dans Kubernetes. Lorsque SQL Server appelle le code Python, il peut à son tour invoquer Azure Machine Learning, et enregistrer le modèle résultant dans la base de données pour l’utiliser dans les prédictions.
MindsDB
Si votre base de données ne prend pas encore en charge l’apprentissage automatique interne, il est probable que vous puissiez ajouter cette fonctionnalité en utilisant MindsDB, qui s’intègre à une demi-douzaine de bases de données et à cinq outils de BI. Les bases de données prises en charge sont MariaDB, MySQL, PostgreSQL, ClickHouse, Microsoft SQL Server et Snowflake. Une intégration avec MongoDB est en cours et des intégrations avec des bases de données en continu sont promises pour 2021. Les outils de BI pris en charge sont actuellement SAS, Qlik Sense, Microsoft Power BI, Looker et Domo.
MindsDB propose AutoML, les tableaux d’IA et l’IA explicable (XAI). Vous pouvez invoquer la formation AutoML à partir de MindsDB Studio, d’une instruction SQL INSERT ou d’un appel API Python. La formation peut éventuellement utiliser les GPU et créer un modèle de série chronologique. Vous pouvez enregistrer le modèle sous forme de table de base de données et l’appeler à partir d’une instruction SQL SELECT sur le modèle enregistré, à partir de MindsDB Studio ou d’un appel API Python. Vous pouvez évaluer, expliquer et visualiser la qualité du modèle à partir de MindsDB Studio. Il est également possible de connecter MindsDB Studio et l’API Python à des sources de données locales et distantes. MindsDB fournit en outre un cadre d’apprentissage profond simplifié, Lightwood, qui fonctionne sur PyTorch. En clair, MindsDB apporte des fonctionnalités utiles de ML à un certain nombre de bases de données qui ne disposent pas d’une prise en charge intégrée de cette technologie.

A l’aide de données historiques, la solution MindsDB aide à prédire l’avenir. (Crédit : MindsDB)
Un nombre croissant de bases de données prennent en charge l’apprentissage automatique en interne. Le mécanisme exact varie, et certains sont plus performants que d’autres. Si vous avez tellement de données que vous devriez autrement ajuster des modèles sur un sous-ensemble échantillonné, alors l’une des huit bases de données énumérées ci-dessus - et d’autres avec l’aide de MindsDB - pourrait aider à construire des modèles à partir de l’ensemble des données sans générer de frais généraux importants pour l’exportation des données.
Oracle Database
Oracle Cloud Infrastructure (OCI) Data Science est une plateforme managée et serverless destinée aux équipes de science des données pour construire, former et gérer des modèles de ML à l’aide d’Oracle Cloud Infrastructure, notamment Autonomous Database et Autonomous Data Warehouse. Elle comprend des outils, des bibliothèques et des packages centrés sur Python développés par la communauté open source et la bibliothèque Oracle Accelerated Data Science (ADS), qui prend en charge le cycle de vie de bout en bout des modèles prédictifs : acquisition, profilage, préparation et visualisation des données ; ingénierie des caractéristiques ; formation au modèle (y compris Oracle AutoML) ; évaluation, explication et interprétation du modèle (y compris Oracle MLX) ; déploiement de modèles vers Oracle Functions.
OCI Data Science s’intègre au reste de la pile Oracle Cloud Infrastructure, notamment aux fonctions, au flux de données, à l’entrepôt de données autonome et au stockage d’objets. Les modèles actuellement pris en charge incluent : Oracle AutoML, Keras, Scikit-learn, XGBoost, ADSTuner (réglage des hyperparamètres). A noter qu’ADS prend également en charge l’explicabilité de l’apprentissage automatique (MLX).
Vertica
Vertica Analytics Platform est un entrepôt de données évolutif à stockage en colonnes. Il fonctionne en deux modes : Enterprise, qui stocke les données localement dans le système de fichiers des nœuds qui constituent la base de données, et EON, qui stocke les données de manière communautaire pour tous les nœuds de calcul.
Vertica utilise un traitement massivement parallèle pour traiter des pétaoctets de données, et effectue son apprentissage automatique interne avec le parallélisme des données. Il dispose de huit algorithmes intégrés pour la préparation des données, de trois algorithmes de régression, de quatre algorithmes de classification, de deux algorithmes de clustering, de plusieurs fonctions de gestion des modèles et de la possibilité d’importer des modèles TensorFlow et PMML formés ailleurs. Une fois que vous avez ajusté ou importé un modèle, vous pouvez l’utiliser pour la prédiction. Vertica permet également des extensions définies par l’utilisateur et programmées en C++, Java, Python ou R ainsi que la syntaxe SQL pour la formation et l’inférence.
Article rédigé par Anirban Ghoshal sur “LE MONDE INFORMATIQUE”.